HIP HOP MUSIC. IS IT ONLY ABOUT DRUGS, SEX AND MONEY?

Rap music (commonly referred to as hip hop music) is a very popular genre of music that has been around since the 1970s. Its origins are generally credited to African-Americans in the South Bronx area in New York City (East side!!)
Did you know: Hip hop music developed as part of hip hop culture. The culture comprised: deejaying (turntabling), MCing (rapping), graf (graffiti paiting), and B-boying (Break dancing).
Of all the components of hip hop culture, rap music has turned out to be the most dominant aspect. It has taken over the world by storm!!!
You can read detailed articles on hip hop, here and here. Also, Why there will never be a GOAT in hip hop
Over time, rap music has come to be associated with violence, sex, drugs, extreme luxury etc. Anectdotally, this might be due to the topics that early hip hop artists were singing about (a case of art of imitating life) and the propagation of myths and stereotypes. Beefs and murders involving people in the hip hop industry has not helped hip hop's case.
But is rap music primarily about drugs, sex, money, and violence? Or is it one of those things we all believe since we hear it all the time? I set out to answer this question by examining music from some 16 rap artists who have been in the industry both new-age and seasoned rappers.
If you can name all the rappers shown in the collage above, comment below for a gift.
The data
Lyrics from all available songs off metrolyrics.com (about 6000 songs) was collected for the following artists (the choice was arbitrary):
Drake, Lil Wayne, Cardi B, Kanye West, Future, Rick Ross, Migos, Eminem
Kendrick Lamar, Dr. Dre, Lil Yatchy, J Cole, Nas, Wiz Khalifa, Jay Z, Nicki Minaj
Join me, and let's find out how inciteful this data can get…
But first, what is in the data?
Let's dig into the data a bit, and see what we find…
Artist activity by year
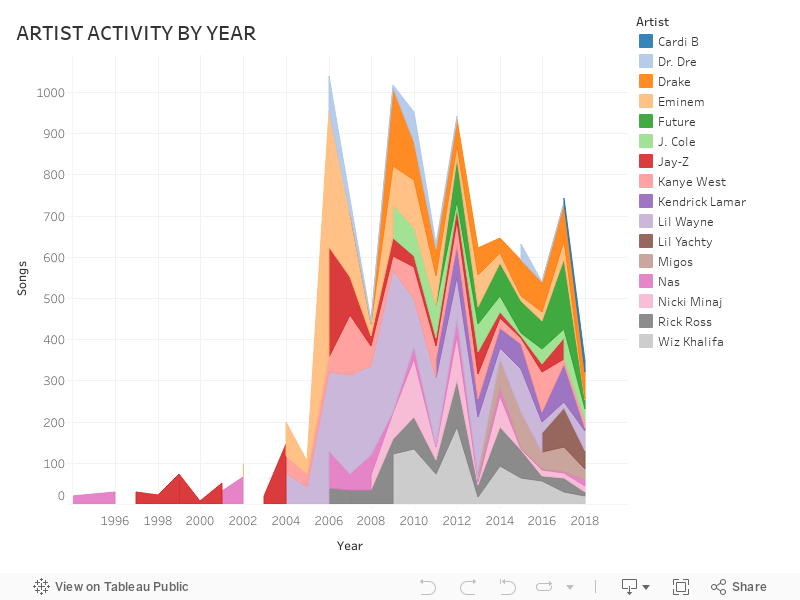
How long are the songs?
Most hiphop songs range from 3 to 5 minutes long, but how many words do they really contain? Excluding common stopwords, here's how the length compared

I understand how Eminem's songs get their length, you know, lyricsm… but Cardi B? That was a shocker!!!
Rappers are beefing aaaaalll the time!! It's pretty much what the rap game thrives on. Are they really that different? Are their public differences really founded, lyrically speaking? Comparisons were done on the 100 most frequently uttered words for the following:
Jay Z vs Nas
 |
 |
Not much difference… at face value anyway
Cardi B vs Nicki Minaj
 |
 |
Cardi's really into money, bags, and herself.. One could attribute that to her still being fresh in the game.
Notice how the ladies have higher occurence of the words b**** while the guys utter ni**** more.
You can view all word maps, here. J. Cole's map will shock you!!
Artist's music sentiment
Rap music is generally considered negative. But how negative is it, really?
Each word (exlcuding stopwords) was given valence (-5 most negative to +5 most positive) and an aggregate value for all lyrics calculated.

Excluding Cardi B and Lil Yatchy (since they don't have as many songs as the rest) Kanye is quite positive!! Hell yea, Yeezy. Lil Wayne is (not surprisingly) not doing very well.
Onto the question of this post…
What is hiphop?
Let's start with the simplest approach… What are the most frequently used words by ALL the rappers under examination?
Well, that doesn't tell us much, now does it?

To have an (approximately accurate) answer in the easiest way possible, let's break down the lyrical content:
Hiphop music. A lyrical breakdown
For all the music collected, the average length of a song was computed i.e. how many words a song contains (excluding stopwords). The lyrical content was then broken down into drugs, sex, money, and the rest. Each category was computed by checking for existence of words of that category per song e.g. count the number of times 'weed, joint, henny' etc exist in a song, to check for drugs.
Here are the results…

Each block is one word.
For an average length of 128 words, only 7 words are about drugs, sex, and money. I was surprised too!!!
Worst offenders
Now that we've seen what hiphop really is about, which turned out not to be what 'facts' have been telling us this whole time, who are the worst offenders? How do the artists rate in their usage of lyricsm about sex, drugs, and money?

Excluding Cardi B and Lil Yatchy (since they don't have as many songs as the rest) notice how Kanye has the least occurence, and also the most positive music? Again, go Yeezy!!!!
So, is hiphop only about drugs, sex, and money?
A word
16 artists cannot represent the entirety of the hiphop industry, so take these results with a grain (or two)of salt!!!
Kanye rocks!!!
The following section is an in-depth explanation/ tutorial of how everything in this post was done… code, technique and all. If uninterested, you may skip to the comments section here.
THE TUTORIAL
In this section, I provide a full tutorial on how to recreate exactly what I did
Prerequisites:
Python >2.7
The code repository off Github, here
Basics of web crawling using Scrapy (start here)
1. DATA COLLECTION
Refer to LyricCrawler/A. SETUP
- For this project, Scrapy was the primary data collection tool. Set-up, create project and move into itpip install scrapy scrapy startproject scraperName cd scraperName
B. METROLYRICS.COM SITE STRUCTURE
- To collect the lyrics, first, the artists were chosen. I ended up with a list of 16 artists… a mixture of new and old, male and female.- Several lyrics sites were studied. I ended picking Metrolyrics due to its simplicity.
- For each musican, Metrolyrics has a list of their music (every song ever registered on there) and the year of production.
* For instance, Kanye's page… http://www.metrolyrics.com/kanye-west-lyrics.html
Note: The name of the song is a link to a page with the full lyrics of the song
C. CRAWLING
- To crawl and collect all the lyrics- Open the grand list of music by each artist (the URLs were collected manually)
- Collect the years of production and the links to the lyrics off the list
- Go to the lyrics page and copy the lyrics
The output of the spider:

2. DATA CLEANING AND PREPROCESSING
Refer to eda.py cleanDataset() method-The data collected cannnot be used as is. Our primary concern is words therefore we need to remove entries without lyrics, remove stopwords and other unneccessary characters
a) Remove empty entries
import pandas as pd
import numpy as np
#Check for, and remove empty lyrics
df['lyric'].replace('',np.nan,inplace=True)
df.dropna(subset=['lyric'], inplace=True )
b) Remove unneccesary characters and stopwords from lyrics, song and artist namefrom sklearn.feature_extraction import text
#Stopwords
stopWords = text.ENGLISH_STOP_WORDS.union(["I", "like", "I'm", "don't", "ain't", "got", "know", "You", "And", "But", "can't", "just"])
##Remove '\n' from lyric and song name, and stopwords
#From lyric
df['lastLyric'] = df['lyric'].apply(lambda x: ' '.join([word for word in x.split() if word not in stopWords]))
#From name
df['cleanName'] = df['name'].apply(lambda x: x.replace('\n',''))
##Remove the word 'Lyrics'
df['lastName'] = df['cleanName'].apply(lambda x: x.replace('Lyrics', ''))
#From artist
df['lastArtist'] = df['artist'].apply(lambda x: x.replace('Lyrics', ''))
3. EXPLORATORY DATA ANALYSIS
Refer to eda.pySTACKED AREA PLOT VIZ ON TABLEAU
- The stacked area plot of artist activity was plotted using Tableau.
- To plot, the data needs to have year, artist name and number of songs per year
- The data was extracted from our raw dataset using Pandas, as follows
df.drop(['lyric','name','link'], axis=1, inplace=True) #Remove unneeded columns from dataframe
fd = df.groupby(['year','artist']).agg(np.size).reset_index(name='count') #Group data by year and artist, get the aggregate (count) and name the resulting column 'count'
fd.to_csv('data/forChart.csv') #Write data to a CSV file for Tableau
- The generated CSV file is plugged into Tableau to plot a stacked area plot as explained here: Tableau stacked area plotSONG LENGTH
- To compute the average song length of each artist, group lyrics by artist, and get median length of the lyrics.
df['lyricLength'] = df['lyric'].apply(lambda y: len(y.split())) #Get length of each song (Split lyrics into array and count) df.drop(['year','name','link', 'lyric'], axis=1, inplace=True) #Remain with lyrics and artists columns only fd = df.groupby(['artist']).agg(np.median).reset_index() #Group by artist and get median lenght. Create new dataframe- Plot the data using Seaborn
import seaborn as sns
import matplotlib.pyplot as plt
sf = fd.sort_values('lyricLength', ascending=False) #Sort by length of lyrics
g = sns.barplot(x=sf['artist'], y=sf['lyricLength'], data=sf) #plot
g.set_xticklabels(sf['artist'], rotation=15)
plt.title("ARTIST SONG LENGTH")
plt.ylabel("SONG LENGTH (MEDIAN)")
plt.xlabel("ARTIST")
plt.show()
WORD CLOUDS
CREATING WORD MAP
- To draw compelling and insightful wordclouds, clouds that match what is being represented are very ideal e.g. having a world cloud spelling out 'Nas' when doing a frequency analysis for the artist Nas.
- The word to be spelled out is called a map, and can be generated from text using Open CV.
a) Install OpenCV
pip install opencv-pythonb) Generate map
- The most important function is the putText() function that generates an image when given a string.
import cv2
ln = len(nm)
#nm is the string to draw
img = np.zeros((612, ln*420, 3), np.uint8)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,nm,(0,500), font, 18, (255,255,255),85)
img = 255-img
cv2.imwrite('name.jpg', img)
- The generated image by OpenCV is then written to a file 'name.jpg' for later usePOPULATING MAP
Refer to eda.py drawCloud() method
- Once the map (the image) is generated, it's time to use it to show frequencies on it.
- The WorldCloud Library comes in handy
pip install wordcloud- Populate the map
from wordcloud import WordCloud
img = Image.open("name.jpg")
hcmask = np.array(img)
wordcloud = WordCloud(mask=hcmask, min_font_size=10, background_color=None, mode='RGBA', colormap='gist_rainbow').generate(corpus)
MUSIC SENTIMENT
Refer to eda.py senti() method
- Sentiment in words can be approached in so many ways, everything from asking people to building machine learning models
- For this post, I wanted to do the bare minimum… calculate the level of negativity (or positivity) in a song. This too can be approached in so many ways. I chose the easiest way possible.. what if you assign each word a level of valence (from –5 most negative to +5 most positive) then aggregate? Well, this guy did exactly that, and he wrote a python module for it!!!
Here's the idea:
a) Get all music for each unique artist as a single string
b) Calculate the score(sentiment) for each string
c) Store the artist and score in a dictionary
d) Plot that mafaka!!
from afinn import Afinn affin = Affin() #The code goes here. It refuses to render properly on here. Check out Github
LYRICAL BREAKDOWN
Refer to eda.py occurences() method
- The idea behind lyrical breakdown is simple: Add the existence of words about sex, drugs, or money per song the do an analysis
#Define words to look for. This should be expanded. drugs = ['weed', 'blunt', 'pot', 'chronic', 'ganja', 'cannabis', 'henny', 'hennessy', 'cristal', 'patron', 'bacardi', 'moet', 'molly', 'crack', 'cocaine', 'ganja', 'mdma', 'ecstasy', 'purple', 'coke'] sex = ['pussy', 'hoes', 'bitches', 'bitch', 'booty', 'balls deep', 'sex', 'ass', 'bone', 'DTF', 'fucking'] money = ['money', 'dough', 'bands', 'benjamins', 'cheddar', 'buck', 'bucks', 'dinero', 'pesos', 'quid'] #Calc item occurence df['lyricLength'] = df['lyric'].apply(lambda y: len(y.split())) df['drugs'] = df['lyric'].apply(lambda x: hesabu(drugs, x)) #Repeat for sex and money. #The new columns contain a set,containing the total occurence of all words and a dict of the specific words and their counts. Access them appropriately for percentages n shii #The function hesabu()... from Collections import Counter hesabu(needle, haystack): count = dict(Counter(haystack.split()).most_common()) items = dict() total = 0 for key in count.keys(): if(key in needle): items[key] = count.get(key) total = total + count.get(key) return items, total
- VISUALISING
- Let's draw some charts!!!!
- THE WAFFLE CHART
- This is a chart that literally looks like a waffle and is a fantastic replacement for waffle charts. Check the Python implementation here
Install the bitch
pip install pywaffle- Calculate the values to be represented i.e. average values of song length, occurence of sex, drugs, and money
medianLen = math.ceil(np.average(df['lyricLength']))
drugs = math.ceil(np.average(df['drugsTotal']))
sex = math.ceil(np.average(df['sexTotal']))
money = math.ceil(np.average(df['moneyTotal']))
rest= medianLen - (drugs+sex+money)
data = {'Drugs' : drugs,'Sex' : sex, 'Money': money, 'Others' :rest}
- Build the chart
from pywaffle import Waffle
fig = plt.figure(
FigureClass=Waffle,
rows=4,
columns=71,
values = data,
colors = ('#ff0000', '#0000cc', '#006600', '#000000'),
legend = {'loc': 'lower left', 'bbox_to_anchor': (0, -0.4), 'ncol': len(data), 'framealpha': 0}
)
plt.title('A BREAKDOWN OF LYRICAL CONTENT FOR A SONG')
plt.show()
- THE BAR CHART
- You're all grown up now. You can figure this one out!!!
I'm super stoked you did this looking forward to read more of your work.
ReplyDeleteThank you! Stay tuned for more!
DeleteThis comment has been removed by the author.
ReplyDeleteData analytics is super magic!! I mean who'd have thought that hip hop is not really about money,sex and drugs? Until you read between the "python" lines(if you know what i mean :) )
ReplyDeleteI was shocked too!!
DeletePython is magic...The new oil in any company ....On a light note..Eminem be the inspiring for years..no nude,money,sex or drugs...just super words that touches my heart.
ReplyDeleteGreat Work Gaks...Analysis is spot on
ReplyDelete